
| 开始时间: | 2018-01-07 13:00 星期日 |
|---|---|
| 结束时间: | 2018-01-07 17:30 星期日 |
| 举办地点: | www.hellobi.com |
| 主办方: |
天善智能
|
购买地址:
深入浅出、点金赋能!Hadoop体系大数据开发案例实战 https://edu.hellobi.com/course/242
深入浅出、点金赋能!Hadoop体系大数据开发案例实战
【温馨提示:1. 你可以在PC端浏览器或者微信收藏该页面,以方便你快速找到这个课程;2. 课程相关资料&QQ会员群可在课程PC端公告查看下载;3.购买课程后,点(课时)列表即可观看视频 】
课程目标:
概览大数据技术生态圈与技术趋势动态;
由浅入深,通过理论及案例学习,掌握大数据基础知识技能、数据库、安装部署、以及HDFS、MapReduce、Hive、Hbase、Kafka等Hadoop生态圈技术,达到项目实战水平。
适合人群:
对大数据感兴趣,大数据管理者,大数据维护者,hadoop开发者,大数据数据挖掘分析的人。不需要具备Hadoop知识,只需要基本的数据库基础知识,基本的java知识。
学习方式:
录播课程,开课即学
在线反复观看,有效期2年
上课方式:录播学习+VIP会员群+独享问答中心+在线答疑 +2年反复观看
课程特色:
金牌讲师。丰富大型企业一线实战,授课专业且细心,五星好评;
体系全面。涵盖预备知识、HDFS、MapReduce、ZooKeeper、Yarn、Hbase、Sqoop、Impala、Hue等Hadoop前后端技术,包括理论与技巧;
规划有序。循序渐进,课程设计由浅入深,细致剖析,逐步掌握各项技术,付诸实战;
精品案例。有质量的案例,代码级的剖析,循循善诱,学习过程中事半功倍;
注重互动。强化学员自身理问题、分析问题及解决问题能力;
讲师介绍:
1、陈建平,拥有12年+数据行业经验,曾服务于IBM、永辉等大型企业,在企业大数据架构规划、数据治理、数据建模、数据挖掘、企业数据仓库及经营分析系统建设有丰富经验和心得。
2、熟悉hadoop、Hbase、HDFS、Hive、Pig、Hue、Spark等开源技术,对实时处理Storm、SparkStreaming有较深的认识,熟悉分布式MapReduce计算引擎。
3、熟悉数据挖掘算法和解决方案。熟悉spss\R语言\SparkMLlib\Python等挖掘语言,熟悉决策树、K-means、神经网络、Logistc线性回归、Apriori算法、协同过滤等多种算法。
4、熟悉零售、电信、移动、电力、证券、网络、物流、医疗、银行等行业。
5、曾为北京电力、福建电信、上汽、苏宁电器、上海烟草、工商银行等提供企业培训服务。
上线时间:
2018年1月7日
定价:
促销价:299元,原价:499
学习方式:
录播课程,开课即学
在线反复观看,有效期2年
上课方式:录播学习+VIP会员群+独享问答中心+在线答疑 +2年反复观看
钱景无限
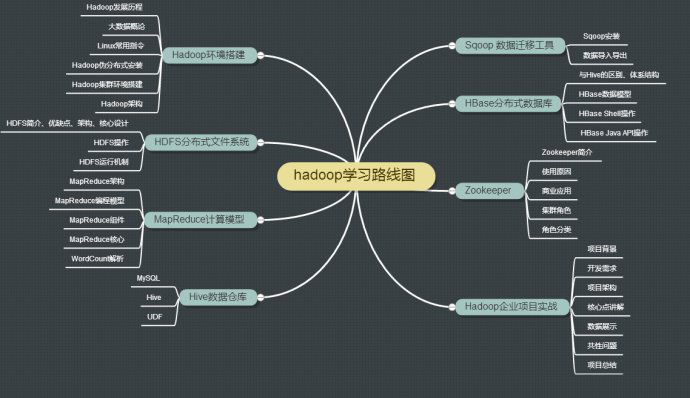
学习路线
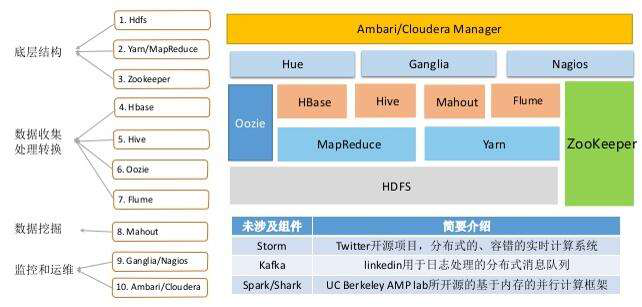

课程大纲:
共30小时
第一章节:Linux基本介绍【60分钟】
1、Linux简介
2、利用VMWare虚拟机搭建学习环境
3、Linux 基本命令
4、编辑器vi/vim
5、shell编程实现
6、Linux系统管理
7、练习:删除上传文件和定时任务调度
第二章节:数据库原理和使用【60分钟】
1、数据库基本概念
2、什么是MySQL数据库
3、MySQL基本操作
4、数据库基础知识概述
5、SQL语言详解
6、练习:创建表并增删改查数据
第三章节:JAVA入门基础【60分钟】
1、什么是Java
2、Java语言的特点
3、什么是JDK
4、第一个Java程序
5、path等环境变量配置
6、标识符和关键字
7、常量与变量
8、Java运算符
9、Eclipse基本介绍
10、Eclipse开发
11、开发helloworld的java程序
12、案例: Eclipse编写实时产生数据java程序并上传服务器
第四章节:大数据的基础介绍【30分钟】
1、什么是大数据
2、大数据时代的背景
3、学术上怎么定义大数据
4、大数据的构成
5、大数据的演进过程
第五章节:大数据带来的影响【30分钟】
1、大数据的关键技术
2、大数据分布式系统的构成
3、计算模式
4、大数据产业
5、大数据与云计算的关系
6、大数据和物联网的关系
第六章节:CentOS系统和Cloudera Manager安装配置【60分钟】
1、VMware虚拟机安装和配置
2、CentOS6、5且64位系统安装
3、简单的配置和遇到的问题
4、动手和实操
5、Cloudera Manager的离线安装
6、案例:动手安装配置CM
第七章节:Cloudera CDH的安装和配置及环境的测试【120分钟】
1、Cloudera CDH的离线安装的环境准备 和配置,注意事项
2、单机版、伪分布式、真分布式介绍和区别
3、详细介绍了CDH的部署配置,遇到的问题,怎么解决
4、HDFS分布式文件系统的安装配置和测试
5、hdfs的权限配置,目录创建,目录查看等命令的使用
6、案例:CDH的安装和配置
第八章节:开源Hadoop生态圈的介绍【60分钟】
1、Hadoop生态圈
2、组件功能概要
3、Cloudera Manager的介绍
4、CM的硬件监控
5、内存监控
6、硬盘监控
7、预警监控
8、集群监控
第九章节:HDFS分布式文件系统详解【60分钟】
1、什么是分布式文件系统HDFS
2、HDFS基本架构
3、基本概念
4、主要涉及理念
5、hdfs常用命令
6、hdfs的上传文件
7、hdfs的下载文件
8、hdfs的查看数据
9、hdfs优点和缺点
10、案例:实现HDFS文件上传和下载
第十章节:ZooKeeper分布式协作服务【60分钟】
1、什么是Zookeeper
2、为什么使用Zookeeper?
3、Zookeeper解耦系统结构
4、Zookeeper特征
5、安装和配置
6、Zookeeper的角色
7、Zookeeper的读写机制
8、Zookeeper的API接口
9、观察者(watcher)
10、Zookeeper工作原理
11、数据同步
12、Zookeeper应用场景
13、案例:运用java程序实现Zookeeper创建更新节点
第十一章节:Yarn资源管理系统【60分钟】
1、什么是Yarn
2、Yarn特点
3、Yarn原理
4、Yarn核心架构
5、优势和不足
6、ResourceManager(RM)介绍
7、ApplicationMaster(AM)介绍
8、NodeManager(NM)介绍
9、Container介绍
第十二章节:Sqoop大数据同步工具介绍【60分钟】
1、Sqoop基本介绍
2、基本原理
3、应用场景
4、Sqoop和mysql的连接
5、mysql数据到HDFS
6、HDFS数据到mysql
7、关系型数据库到hive
8、hive到关系型数据库
9、Sqoop优点和缺点
10、案例:oracle到hdfs的大数据量转换
第十三章节:MapReduce分布式计算框架详解【120分钟】
1、MapReduce基本介绍
2、为什么要用MR
3、MR是什么
4、工作原理
5、Map的原理
5、Reduce的原理
6、MR例子-单词计数
7、MR的优点和不足
8、适用场景
9、案例:统计多个数据文件每个单词出现次数并倒序排列
第十四章节:Hive 数据仓库及案例【120分钟】
1、Hive 基本介绍
1)Hive 是什么
2)Hive 不是什么
3)Hive 结构图
4)Hive 元数据
5)Hive 和普通关系数据的异同
6)Hive 和 SQL 比较
2、Hive 命令
1)建表
2)显示表
3)修改表
4)load 数据
3、Hive 优化
1)分区概念
2)分区适用场景
3)分区例子
4)优化例子
5)优化建议方案
4、Hive 的用户自定义函数
1)UDF 函数
2)UDAF 函数
3)UDTF 函数
5、案例讲解:Hive分区表的优化设计
第十五章节:Impala准实时分析【60分钟】
1、Impala基本介绍
2、技术架构
3、Impala与HIVE的关系
4、基本原理
5、优点和缺点
6、建表
7、加载数据
8、批量处理
9、常用脚本
10、和hive的性能比较
11、和oracle的对比2亿数据性能
12、和oracle的对比12亿数据性能
13、案例:Impala调用外部文件
第十六章节:Hue页面工具详解【60分钟】
1、命令脚本存在的问题
2、为什么需要HUE
3、Hue基本功能
2、Home页面
3、Job Browser页面
4、File Browser页面
5、元数据页面
6、Hive查询页面
7、Impala查询页面
8、创建外部表
9、加载数据
10、查询结果
11、案例:页面实现impala导入导出数据
第十七章节:Hbase列数据库及应用案例【120分钟】
1、Hbase感性认识
1)Hbase简介
2)Hbase特点
3)HBase与RDBMS对比
4)HBase体系结构
5)Hbase常见概念
2、Hbase主要组成
1) HBase基本命令介绍
2) Zookeeper、Hmaster
3) HRegionServer、Region
4) HStore存储、Hfile
5) Hbase内部扫描RowKey的原理
6) Hbase内部读写原理
7) HBase设计原理、架构分析
8) Hadoop+HBase伸缩性(自动扩容、热部署)
9) HBase相关表结构设计(列族、列详细分析)
10) HBase主HMaster与备用HMaster间的切换原理
3、Hbase性能测试
1) 测试数据
2) 测试过程
3) 测试结论
4) 和Oracle Rac等进行对比
4、Hbase设计原则和优化
1) Hbase的RowKey设计原则
2) 性能参数的设置
3) 性能参数的调整
4) 模型和性能优化
5、项目案例:HBase在小米业务的应用
6、项目案例:运营商全国用户上网记录案例介绍
第十八章节:大数据平台部署及案例【60分钟】
1、hadoop有哪几个版本
2、Hadoop版本介绍
3、CDH和Apache版本主要区别
4、集群硬件应该如何选配
1)网络拓扑
2)内存
3)硬盘
4)CPU
5)价格
5、集群硬件应该如何选配
6、英特尔Hadoop发行版的介绍
7、英特尔功能增强
8、项目案例:某省级通信运营商清帐单查询系统
9、项目案例:新清账单中心的部署方案
第十九章节:Kafka详解及应用案例【120分钟】
1、Kafka的基本介绍
1)什么是消息系统?
2)消息队列的分类
3)kafka的基本架构和概念
4)ZooKeeper简介和安装
2、Kafka的原理解析
1)Kafka在ZK上的存储结构
2)Producer的处理逻辑
3)Consumer的处理逻辑
4)Broker的处理逻辑
3、Kafka安装和部署
1)关闭服务
2)下载软件
3)拷贝文件
4)重启服务
5)测试功能是否能用
4、Kafka的Java应用开发
1)Producer端的实现
2)Consumer端的实现
3)程序执行演示
5、Kafka与Hadoop集成
1)Hadoop简介和配置
2)集成Kafka和Hadoop
3)例子演示
6、案例讲解:Kafka与Flume实时统计指定目录文件数据
第二十章节:hadoop衍生数据处理详解【120分钟】
1、ETL 数据处理介绍
1)ETL 导论
2)ETL 概念
3)ETL 逻辑架构
4)exact 方式
5)增量数据捕获方法
6)数据处理方式
7)数据转换
8)缓慢变化维处理
9)数据仓库 Update 处理
10)ETL 优点
2、Kettle 介绍
1)简介 kettle
2)安装和部署
3)运行
3、Kettle 适用
1)菜单介绍
2)转换
3)作业
4)新建 Ktr
5)新建 Kjb
6)Transformation 菜单介绍
7)Transformation
8)Job 菜单介绍
9)Job 组件介绍
4、Kettle 案例
1)案例准备
2)表准备和说明
3)作业建立过程
4)测试结果检验
5)表到文本文件
6)文本文件到表
5、JAVASCRIPT 的基本应用
6、文件 FTP 下载、上传。
7、作业调用作业、转换。
8、启动脚本说明。
9、JAVA 调用作业、转换
10、kettle 使用原则
11、案例:订单数据的上传下载定时处理
1、PC端如果发现浏览器无法观看课程,建议使用谷歌浏览器观看;移动端建议直接微信打开课程页面
2、如果购买后下次登录提示课程需要重新购买,一般是因为你把登录账户记成你绑定的手机或者邮箱帐号而混淆了。
3、【在微信购买课程的用户注意】请微信收藏课程页面或者关注微信公众号:天善智能(点“我的”即可查看你已购买的课程),已方便下次学习。
4、课程相关资料&QQ会员群可在课程PC端公告查看下载;
5、加入学习后请添加客服微信:tianshansoft06(请注明:课程名称),邀请你加入微信VIP群与老师&同学交流讨论;




